這邊使用了最簡單的LlamaIndex建立RAG
本篇可以使用 Colab
!pip install llama-index
!pip install llama-index-llms-gemini llama-index-embeddings-gemini llama-index-embeddings-openai
!pip install GoogleNews
這邊要先掛載你的Google Drive
from google.colab import drive
drive.mount('/content/drive', force_remount=True)
在底下路徑開一個資料夾 /drive/MyDrive/ 名稱為 Colab_Llama_storage
或是自己定義 但
PERSIST_DIR要改成自己的路徑
import os.path
from llama_index.core import (
Settings,
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
from llama_index.llms.gemini import Gemini
from llama_index.core.llms import ChatMessage
from llama_index.embeddings.gemini import GeminiEmbedding
# from llama_index.embeddings.openai import OpenAIEmbedding
PERSIST_DIR = "/content/drive/MyDrive/Colab_Llama_storage"
GEMINI_API = "<YOUR_GEMINI_API>"
# OPENAI_API = "<YOUR_OPENAI_API>"
設定Embedding模型和LLM,並準備和 Storage 原始資料,以便進行 RAG。
GeminiEmbedding 可以設定自己想要的 model,之後 embedding 就會用 gemini 去做,LLM 也同時設定好使用Gemini
if not os.path.exists(PERSIST_DIR):檢查是否存在持久化目錄。SimpleDirectoryReader("docs").load_data():從docs資料夾中讀取原始資料。VectorStoreIndex.from_documents(documents):從文件中建立向量存儲索引。index.storage_context.persist(persist_dir=PERSIST_DIR):將索引持久化到指定目錄。else:如果持久化目錄已存在,則從存儲中載入索引。Code: https://blog.jiatool.com/posts/rag_llamaindex_gemini/
資料準備可以自己拿履歷/一些Data丟進該docs資料夾中。
question = '他原本讀什麼科系?' # @param {type:"string"}
可以使用 Prompt 進行修飾,這樣就不會說得不清楚,也可以讓他簡短回覆。
# Chat
short_response = query_engine.query(question)
messages = [
ChatMessage(role="user", content=question),
ChatMessage(role="assistant", content=short_response),
ChatMessage(role="user", content="請詳細說明"),
]
response = Settings.llm.chat(messages)
# print(short_response)
print(f"assistant 簡短回覆: {short_response} \n\n{response}")
在沒有特別指定的情況下,
以下是對VectorStoreIndex的整理:
默認儲存方法:
索引與查詢:
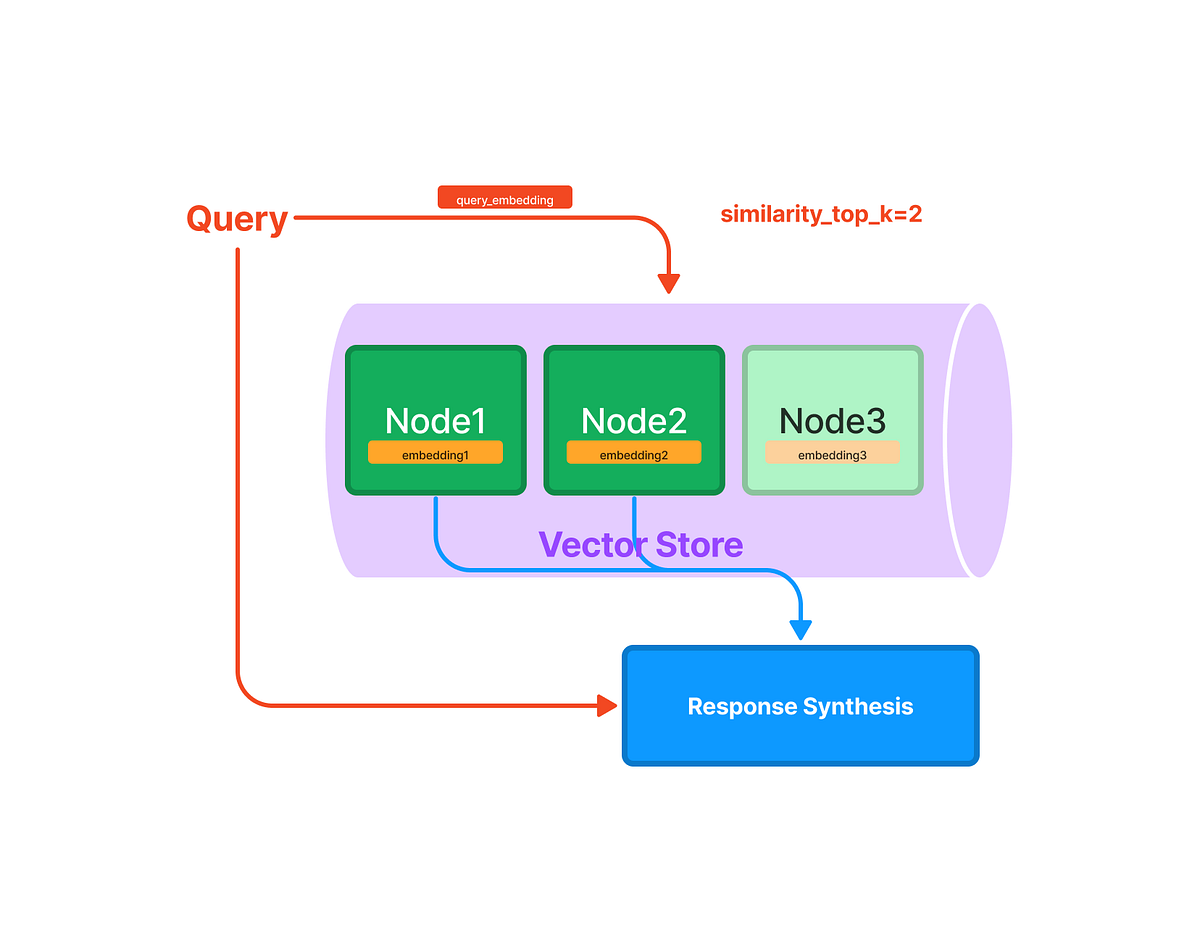
LlamaIndex:
vector_store.persist() 將向量存儲到磁碟,並從磁碟載入 SimpleVectorStore.from_persist_path(...)。查詢過程:
後續也可以使用額外的 prompt 進行調整。
這篇只是做非常簡單的call api,如果要做大型項目,推薦使用比較好管理的資料庫和 Advanced RAG 架構。
如果要部屬的話:
LlamaIndex使用指南
https://llama-index.readthedocs.io/zh/latest/guides/primer/index_guide.html

